Universal Proposition Banks
One of my main research projects is to semi-automatically create the Universal Proposition Banks, a set of treebanks that enable the training of crosslingual parsers and the study of crosslingual semantics. This effort builds on the Universal Dependencies project and adds a layer of crosslingually unified shallow semantic information.
To illustrate what Universal Proposition Banks are, consider the following sentences:
- Letzte Woche habe ich den Futon bestellt. (German)
- Vahtimestari tilasi taksin. (Finnish)
- 同年12月29日, 美國大陸航空 訂購 10架787. (Mandarin Chinese)

We formalize these crosslingual shallow semantics using Proposition Bank frame and role labels. Check out version 1.0 of the Universal Proposition Banks, publicly available here!
We use a semi-automatic annotation projection approach to generate these resources. The approach is described in detail in our publications:
Generating High Quality Proposition Banks for Multilingual Semantic Role Labeling. Alan Akbik, Laura Chiticariu, Marina Danilevsky, Yunyao Li, Shivakumar Vaithyanathan and Huaiyu Zhu. 53rd Annual Meeting of the Association for Computational Linguistics, ACL 2015. [pdf]
Towards Semi-Automatic Generation of Proposition Banks for Low-Resource Languages. Alan Akbik and Yunyao Li. 2016 Conference on Empirical Methods on Natural Language Processing, EMNLP 2016.
Multilingual Aliasing for Auto-Generating Proposition Banks. Alan Akbik, Xinyu Guan and Yunyao Li. 26th International Conference on Computational Linguistics, COLING 2016. [pdf]
The Projector: An Interactive Annotation Projection Visualization Tool. Alan Akbik and Roland Vollgraf. 2017 Conference on Empirical Methods on Natural Language Processing, EMNLP 2017. [pdf][video]
Multilingual Information Extraction
 Our core research is in determining a semantic feature space that is shared between all languages.
Such a feature space may be
explicit and human-readable, as is the case of the Universal Proposition Banks, or induced such as a
high dimensional embedding space.
Given such a shared feature space, we can develop an extractor only once, but immediately run it on
multilingual text without
any
language-specific adaptation. The Figure on the left shows such an extractor in our PolyglotIE
system.
Our core research is in determining a semantic feature space that is shared between all languages.
Such a feature space may be
explicit and human-readable, as is the case of the Universal Proposition Banks, or induced such as a
high dimensional embedding space.
Given such a shared feature space, we can develop an extractor only once, but immediately run it on
multilingual text without
any
language-specific adaptation. The Figure on the left shows such an extractor in our PolyglotIE
system.
Check out screencasts of the system:
The corrsponding publication is found here:
Multilingual Information Extraction with PolyglotIE. Alan Akbik, Laura Chiticariu, Marina Danilevsky, Yonas Kbrom, Yunyao Li and Huaiyu Zhu. 26th International Conference on Computational Linguistics, COLING 2016. [pdf][video]
Crosslingual Semantic Parsing
An Information Extraction system such as PolyglotIE cannot work without a crosslingual parser that parses text in different languages into a shared, language-independent abstraction. Much of our research has focused both on developing a high quality parsing system, as well as training it for different languages. This work has resulted in the state-of-the-art K-SRL parsing approach and the Polyglot semantic role labeler.
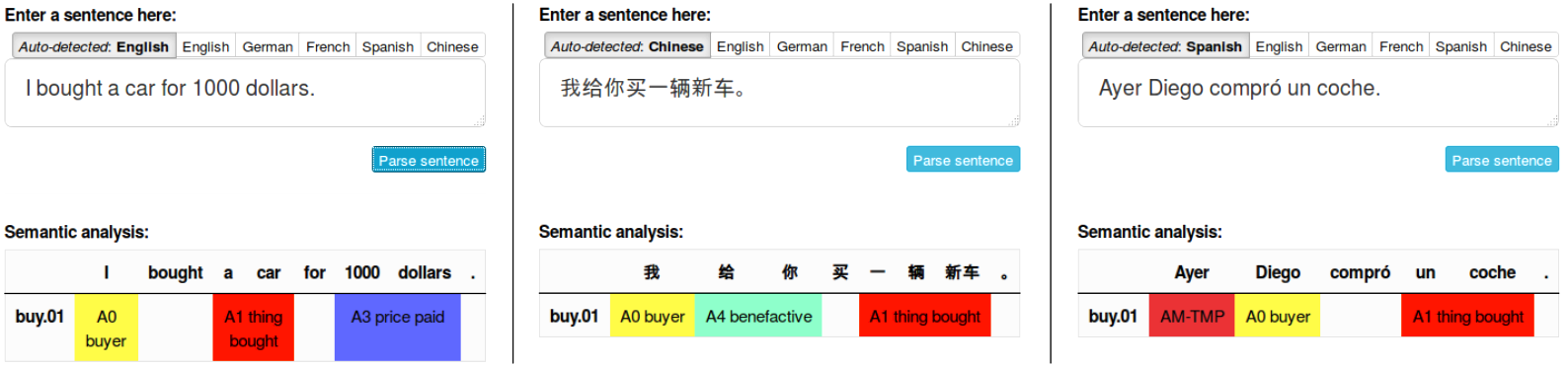
Polyglot is currently capable of semantically parsing 9 different languages. Check out the three screenshots above for example sentences in English, Mandarin Chinese and Spanish. The same semantic concepts are recognized across languages, allowing us to build extractors on top of parser output. The corresponging publications are as follows:
K-SRL: Instance-based Learning for Semantic Role Labeling. Alan Akbik and Yunyao Li. 26th International Conference on Computational Linguistics, COLING 2016. [pdf]
Polyglot: Multilingual Semantic Role Labeling with Unified Labels. Alan Akbik and Yunyao Li. 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016. [pdf]
Alan Akbik
Professor of Machine Learning
Humbold-Universität zu Berlin
alan [dot] akbik [ät] hu-berlin [dot] de