
Research
My research focuses on efficient and practical machine learning for NLP. This includes research into resource-efficient training of large language models (LLMs) and state-of-the-art methods for information extraction (IE) from text. In particular, my group likes to develop tangible output in the form of open source libraries, publicly available datasets and online platforms. See highlights below!
Flair NLP
We develop Flair, a very popular library for state-of-the-art NLP. It is used in thousands of industrial, academic and open source projects.
Boldt
Boldt is a series of state-of-the-art German language models, trained at HU!
Fundus
Need to crawl online news? With Fundus, you can crawl millions of pages of online news with just a few lines of code!

CleanCoNLL
CleanCoNLL is a nearly noise-free dataset for named entity recognition (NER). Use it to train and evaluate your NER models!

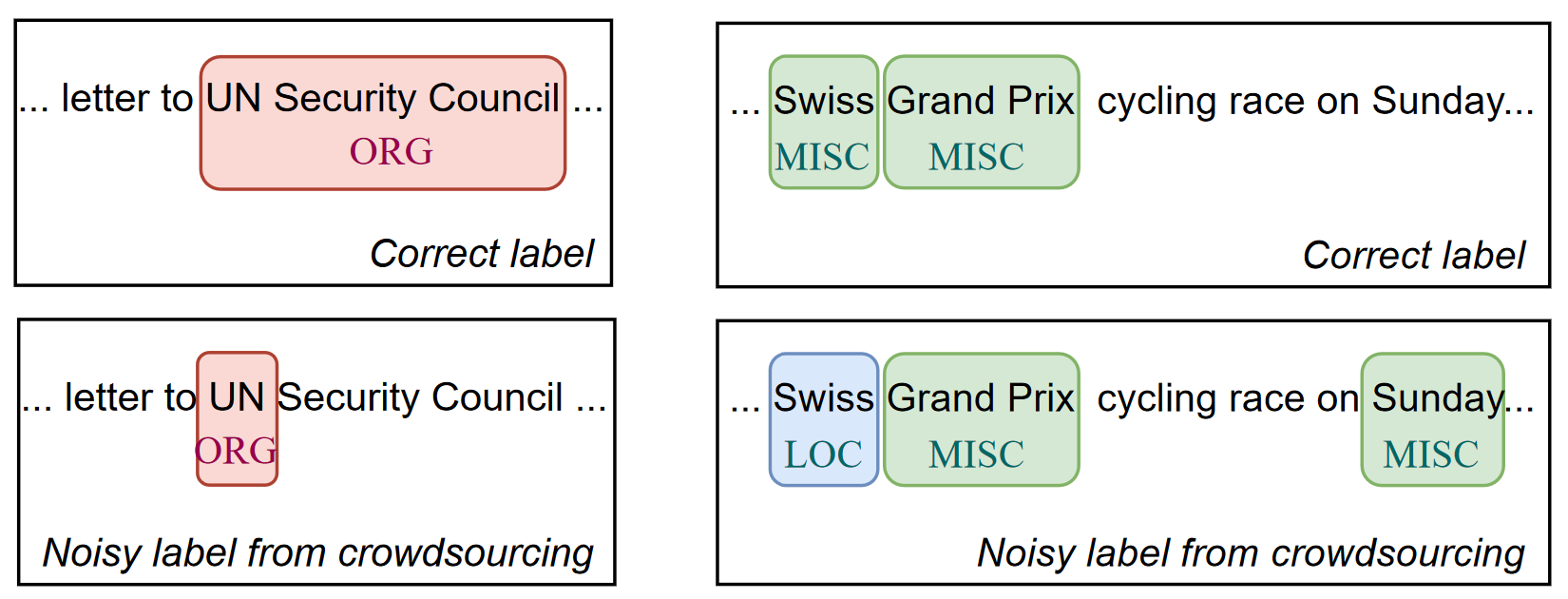
NoiseBench
With NoiseBench, you can measure the robustness of your ML approach to real-world label noise!